Introduction
Data granularity¶
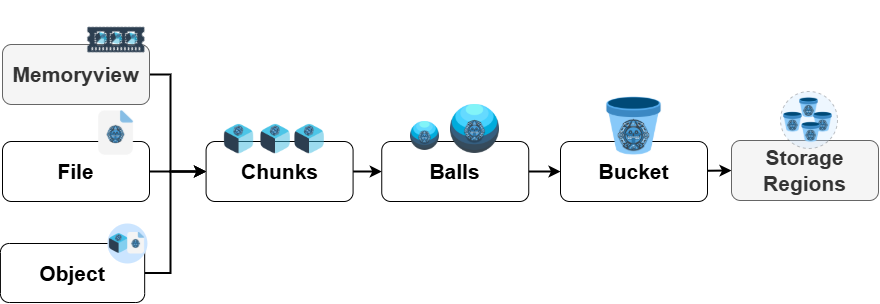
In MictlanX, every payload you store—whether it starts as a memoryview, a file, or an object—is first segmented into fixed-size chunks (e.g., 256KB, 1MB). Each chunk is indexed (0..N-1) so it can be transmitted, retried, and verified independently. These chunks are then assembled into a “ball”, which is the logical object the system manages. A ball is identified by the pair (bucket_id, ball_id) and carries both metadata (size, checksum, content type, tags like fullname, extension, num_chunks, full_checksum) and data (the ordered set of chunks). Individual chunk keys follow the convention {ball_id}_{index} —for example, b1_0, b1_1, …—which makes random access and streaming straightforward.
Multiple balls live inside a bucket, which serves as the namespace and lifecycle boundary for related data. Buckets then reside within a Virtual Storage Space (VSS)—the execution domain that maps and replicates balls across storage peers. This layered design (chunks → balls → bucket → VSS) lets the client pipeline large objects efficiently, recover from partial failures with fine-grained retries, verify integrity end-to-end via checksums, and scale reads/writes across healthy peers without changing application-level semantics.
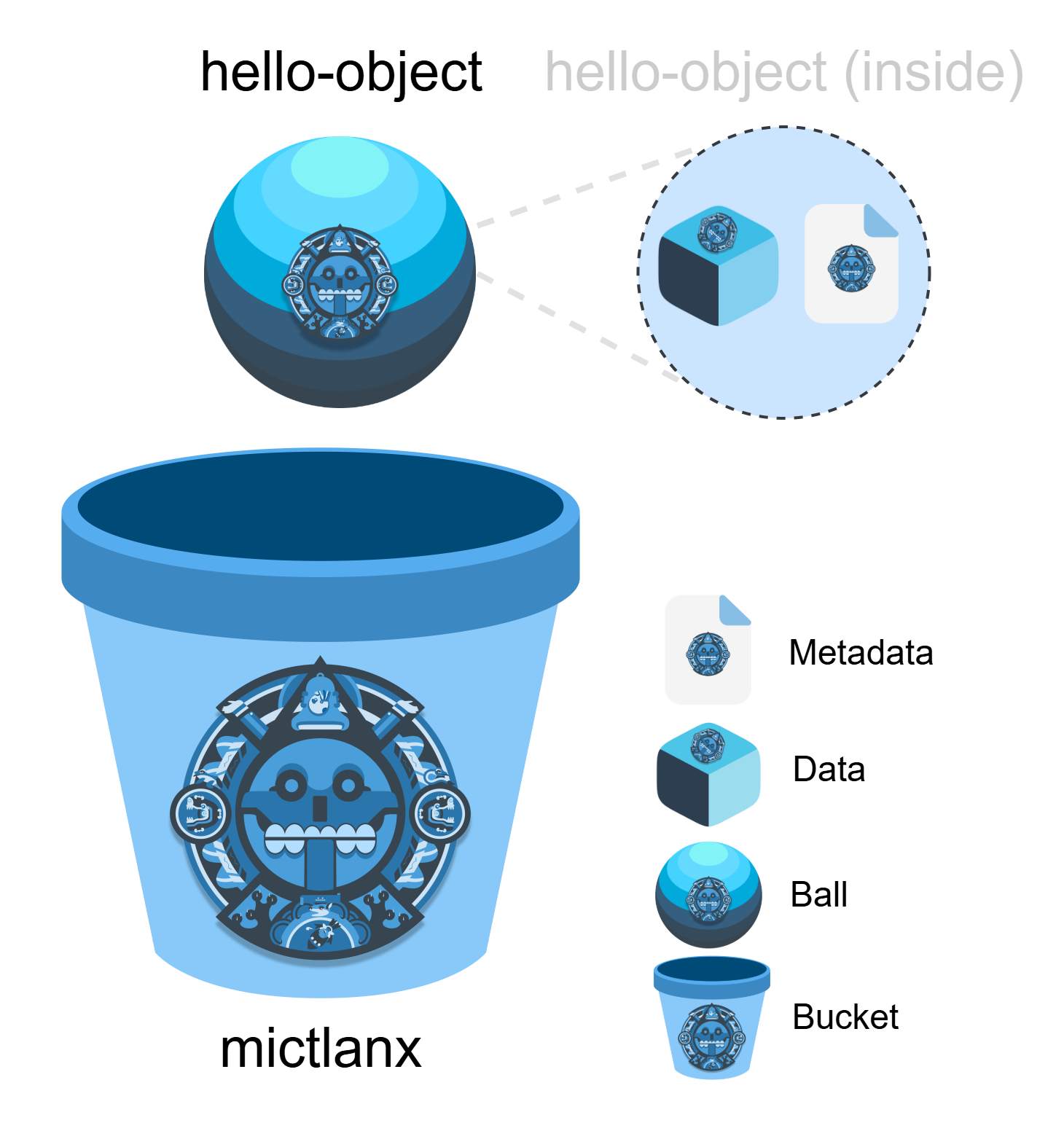
Basic Storage Units
The figure shows how objects (balls) are represented inside the system:
- Metadata: A lightweight description of the ball. Think of it as the label on the ball.
- Data: The actual bytes of the ball. Can be streamed in ranges/chunks.
- Ball: A combination of Metadata + Data. This is the storage unit that lives in a bucket. Each ball is uniquely identified by its
(bucket_id, ball_id)tuple. - Bucket: A logical namespace that groups many balls together. Equivalent to a folder or container, identified by
bucket_id.
Grouping balls 🔵¶
Idea: many balls (objects) can share the same ball_id. That groups them into one logical unit (a set, a timeline, a version, etc.). Each ball still has its own key, metadata, and data.
A bucket stores many balls. If you reuse the same ball_id across several balls, they become a group:
- Each ball has its own key, size, checksum, content_type, and tags.
- All balls with the same (bucket_id, ball_id) belong to the same collection.
- You can list/retrieve them by ball_id to process them together.
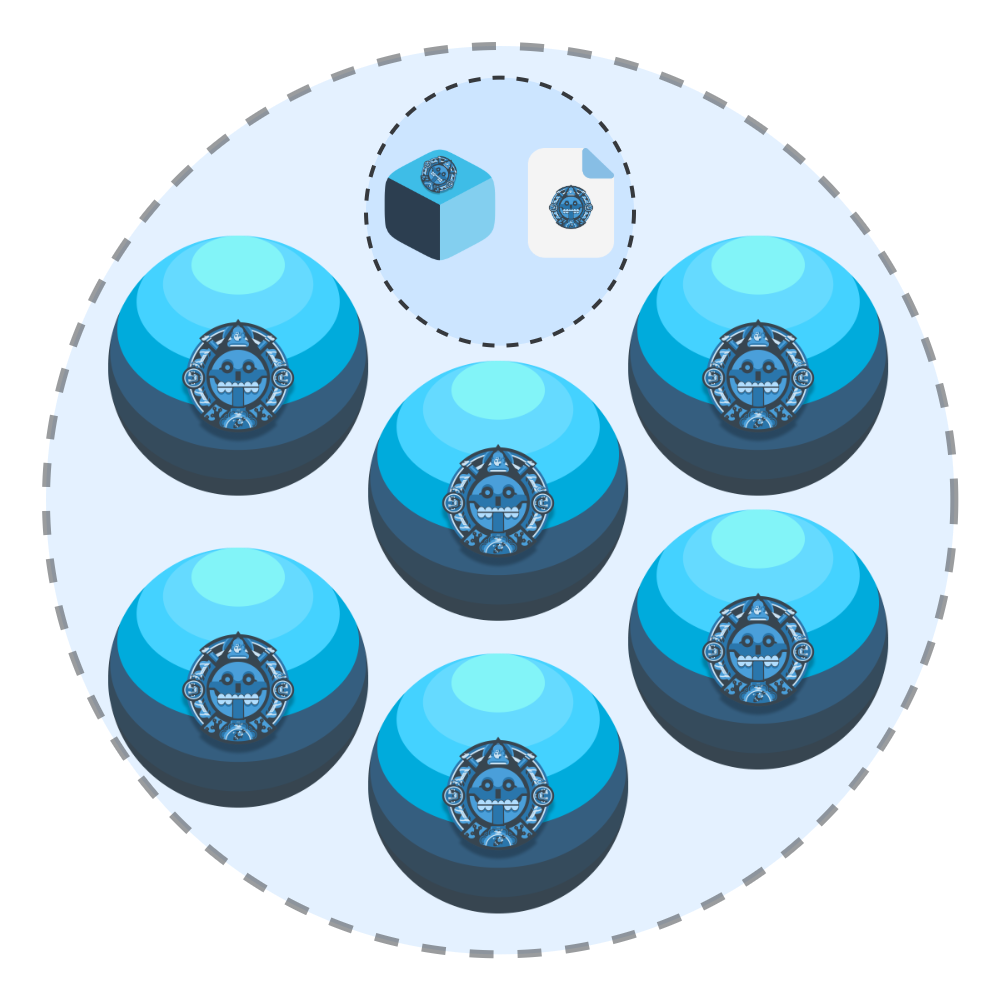
Fig. Group of balls by Ball ID.